All electronics ship with US style plugs.You may need a voltage converter or a plug adapter.
Special Features
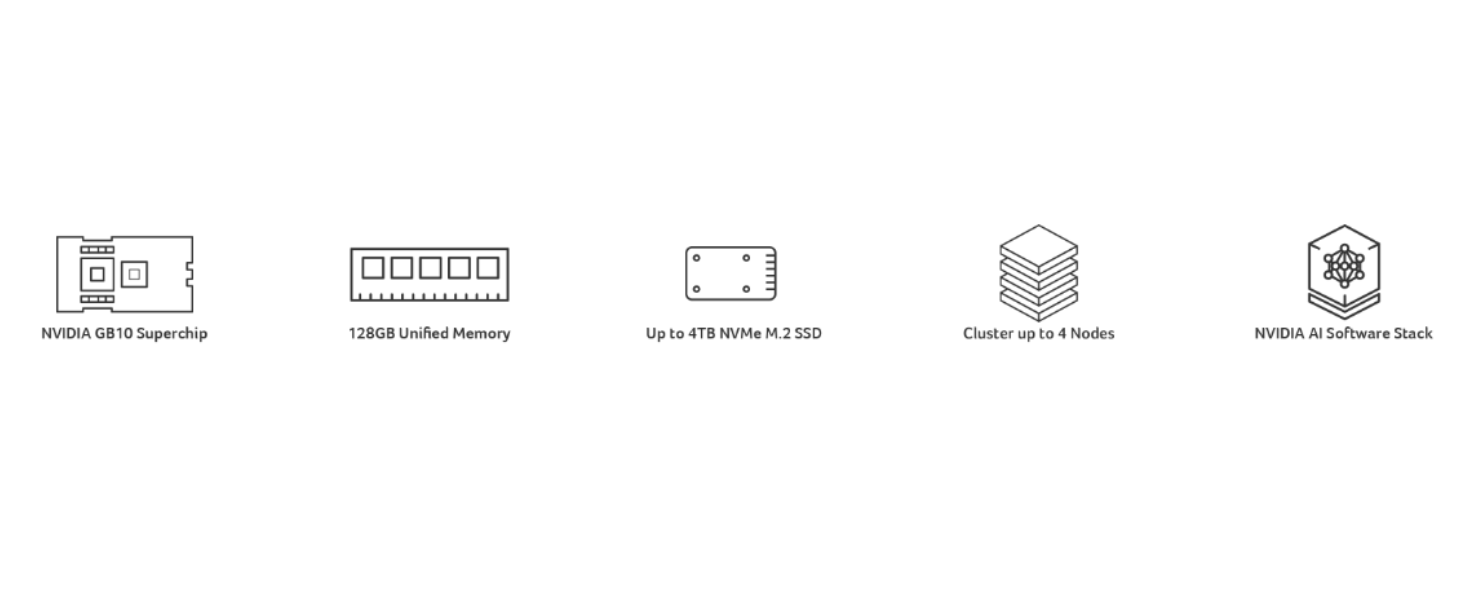
Experience the raw power of the NVIDIA GB10 Grace Blackwell Superchip. Delivering 1 PFLOPS of FP4 AI performance, this workstation handles 200B+ parameter models locally with sparsity. This is the same architecture powering the world's most advanced data centers, brought directly to your desk for zero-latency development.
Pre-installed with NVIDIA DGX OS, the GN100 is tuned for the full NVIDIA AI stack—CUDA, PyTorch, NIM microservices, and the NeMo Framework. The NVIDIA GB10 Grace Blackwell Superchip pairs a 20-core Arm CPU with a Blackwell GPU featuring fifth-generation Tensor Cores, delivering 1 PFLOP of FP4 AI performance with sparsity. Prototype reasoning models locally and deploy to DGX cloud or data centers with zero code changes.
Eliminate the bottleneck between CPU and GPU. The GN100 unified memory architecture lets the Blackwell GPU and 20-core Arm CPU access a shared 128GB pool of LPDDR5X-8533 memory over NVLink-C2C—coherent, addressable, and bottleneck-free. This architecture enables 200B+ parameter models to run locally on hardware that would choke a standard desktop, providing the capacity and bandwidth required for real-time inference at scale.
Two 200Gbps ConnectX-7 ports. Direct-attach a second GN100 for 405B-parameter inference. Add a RoCE 200 GbE switch and link up to four units in a high-speed cluster—the standard configuration for university labs and B2B teams scaling distributed training. Combined with 128GB of LPDDR5X coherent unified memory per node, the GN100 scales as your models scale. Quiet luxury, server-class throughput.
For proprietary models and regulated datasets, every byte stays on-device. The GN100 ships with a 4TB self-encrypting NVMe SSD, an integrated Kensington lock, and a tamper-resistant 1.2kg sealed chassis. Pair with NVIDIA NemoClaw for sandboxed agentic workflows and policy-based privacy controls. Build, fine-tune, and run sensitive workloads without a single packet leaving your lab.
The GN100 uses a high-mass cast-metal thermal solution paired with vertical slat airflow to outperform conventional desktop cooling. Independent third party testing (StorageReview, March 2026) confirms the GN100 stabilizes GPU thermals at 69°C even under heavy AI loads. By preventing thermal throttling, the GN100 ensures complex training and inference tasks run at peak velocity from start to finish — without performance drops.

 Dell Inspiron 7730 27" Touchscreen All in One Desktop Computer, Intel 10-Core 7 150U, NVIDIA GeForce MX570A, 32 GB RAM, 2 TB SSD, Wi-Fi 6E, Win 11 Pro, Office 2024 Pro Lifetime, Wireless KB and Mouse
SAR 7,500
Dell Inspiron 7730 27" Touchscreen All in One Desktop Computer, Intel 10-Core 7 150U, NVIDIA GeForce MX570A, 32 GB RAM, 2 TB SSD, Wi-Fi 6E, Win 11 Pro, Office 2024 Pro Lifetime, Wireless KB and Mouse
SAR 7,500
 acer Aspire TC-1660 2022 Desktop 6-Core 10th Generation Intel Core i5-10400 Intel UHD Graphics 32GB DDR4 1TB SSD Wi-Fi | DVD-RW Windows 10 Home Black w/ONT 32GB USB
SAR 3,625
acer Aspire TC-1660 2022 Desktop 6-Core 10th Generation Intel Core i5-10400 Intel UHD Graphics 32GB DDR4 1TB SSD Wi-Fi | DVD-RW Windows 10 Home Black w/ONT 32GB USB
SAR 3,625
 Acer Aspire TC-885-ACCFLi5O Desktop, 8th Gen Intel Core i5-8400, 8GB DDR4 + 16GB Optane Memory, 2TB HDD, 8X DVD, 802.11ac WiFi, Windows 10 Home
SAR 3,252
Acer Aspire TC-885-ACCFLi5O Desktop, 8th Gen Intel Core i5-8400, 8GB DDR4 + 16GB Optane Memory, 2TB HDD, 8X DVD, 802.11ac WiFi, Windows 10 Home
SAR 3,252
 Acer Aspire TC-1750-UR12 Desktop | 12th Gen Intel Core i5-12400 6-Core Processor | 16GB 3200MHz DDR4 | 512GB NVMe M.2 SSD | 8X DVD | Intel Wireless Wi-Fi 6E AX211 | Bluetooth 5.2 | Windows 11 Home
SAR 3,397
Acer Aspire TC-1750-UR12 Desktop | 12th Gen Intel Core i5-12400 6-Core Processor | 16GB 3200MHz DDR4 | 512GB NVMe M.2 SSD | 8X DVD | Intel Wireless Wi-Fi 6E AX211 | Bluetooth 5.2 | Windows 11 Home
SAR 3,397







